


What is a Text-To-Speech Software?
Text-To-Speech (TTS) Software is a technology that converts written text into spoken words. It uses artificial intelligence algorithms and voice synthesis technology to generate synthetic speech that sounds similar to a human voice. The speech can be played through speakers or saved as an audio file. In addition, the software can be customized to sound like specific languages or voices. Text-To-Speech (TTS) Software can be used for various applications such as reading aloud e-books, enhancing accessibility in education, and improving the customer experience in call centres and IVRs.
Features of a Text-To-Speech Software
List of Text-To-Speech Software
When you start looking for the best text-to-speech software, it is easy to get overwhelmed with the list of options available. Here is the handpicked list of text-to-speech software to choose as per your requirement:
1. Amazon Polly
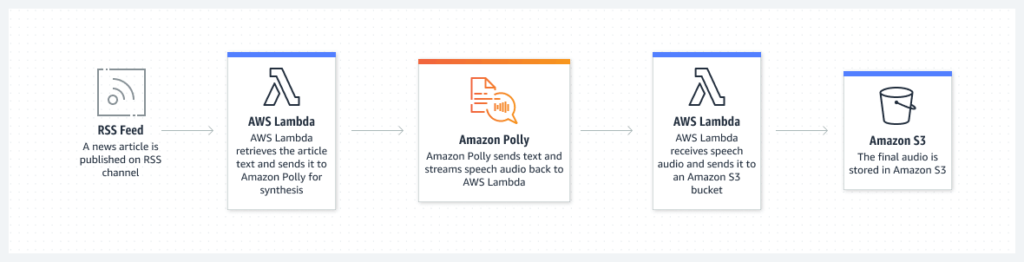
Amazon Polly is a cloud-based text-to-speech (TTS) service offered by Amazon Web Services (AWS). It converts written text into natural-sounding speech in various languages and voices. Polly uses advanced deep-learning technologies to produce speech that sounds like a human voice. In addition, it offers a wide range of customization options for adjusting speech rate, pitch, volume, and pronunciation.
Amazon Polly enables you to easily add speech capabilities to your applications, websites, and products, enabling features such as voice navigation, audiobooks, and announcements. In addition, the service is highly scalable, and you can use it to generate speech in real-time or to store speech files for later use.
Key Features:
- Amazon Polly is fully integrated with other AWS services, making it easy to use and integrate with existing AWS infrastructure
- Allows developers to customize and control various aspects of speech generation, including prosody, speed, and volume, to create a unique and personalized experience
- Provides a simple API that allows developers to add speech capability to their applications without requiring complex integration or specialized knowledge
- It supports various languages and provides a large selection of voices in each language, allowing developers to choose the voice that best fits their needs
To know more about Amazon Polly Text-To-Speech Software features and product options, click here to continue.
2. Google Text-To-Speech
Google Text-to-Speech is a technology developed by Google that converts written text into spoken words using artificial intelligence algorithms and machine learning models. It is available on various platforms, such as Android, Chrome, and Google Assistant-enabled devices. The technology supports multiple languages and customizes speech rate, pitch, and volume options. Google Text-to-Speech software can be used for accessibility, language learning, or adding a voice to applications and devices.
Key Features:
- Google Text-to-Speech is a cloud-based service which allows it to scale dynamically based on demand and offer low latency and high availability
- It supports various languages, including English, Spanish, French, German, and more
- It can be integrated into various applications and devices, including mobile phones, smart speakers, and web applications
- The technology produces human-like speech that is natural and expressive
To know more about Google Text-To-Speech Software features and product options, click here to continue.
3. IBM Watson
IBM Watson Text-to-Speech is a cloud-based solution that converts written text into spoken speech. It uses artificial intelligence and advanced deep-learning algorithms to produce natural-sounding speech in multiple languages. It can be integrated into various applications, such as virtual assistants, mobile apps, and interactive voice response systems. With its high accuracy and customizable voice models, Watson Text-to-Speech software enables developers to create engaging and human-like conversational experiences.
Key Features:
- Allows users to customize the tone and intonation of the speech output, making it possible to create expressive and emotional speech
- It supports the Speech Synthesis Markup Language (SSML) standard, allowing you to specify pronunciation, intonation, and other aspects of speech output
- Watson Text-to-Speech can easily integrate into applications, devices, and workflows through REST APIs and SDKs
- Supports multiple languages, including English, Spanish, French, German, Italian, Portuguese, and Japanese
To know more about IBM Watson Text-To-Speech Software features and product options, click here to continue.
4. Microsoft
Microsoft Speech refers to a range of speech technologies and products developed by Microsoft, such as speech recognition, speech synthesis, and speaker recognition. These technologies are designed to enable human-computer interaction through spoken language and can be used for various applications, including virtual assistants, accessibility features, and hands-free control of devices. Allows users to dictate text, control devices, and perform other tasks using only their voice.
In addition, Microsoft text-to-speech software uses natural language processing (NLP) technologies to understand the meaning behind spoken words, making it easier for users to interact with their devices more naturally and intuitively.
Key Features:
- Microsoft Speech supports multiple languages, making it accessible to a global audience
- Also provides a set of APIs for developers to build speech-enabled applications and services, making it easier to integrate speech technologies into a wide range of applications
- It provides a text-to-speech synthesis that enables users to listen to written text in a natural-sounding voice
- Compatible with many devices, including desktop and laptop computers, smartphones, and internet of things (IoT) devices
To know more about Microsoft Text-To-Speech Software features and product options, click here to continue.
5. NaturalReader
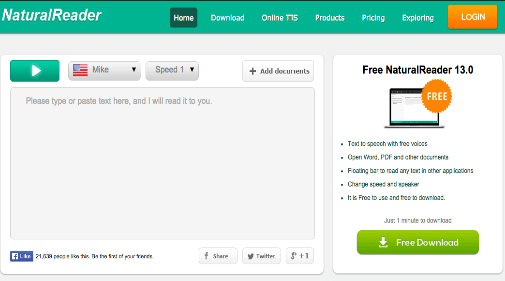
NaturalReader is a text-to-speech software that converts written text into spoken words. It uses advanced text-to-speech technology to generate high-quality speech output. The software can read texts, web pages, and documents, making it useful for individuals who have difficulty reading or want to listen to texts while multitasking. In addition, NaturalReader text-to-speech software offers a range of features, including the ability to change the voice and speed of the speech, save audio files in various formats, and even create audiobooks.
Key Features:
- It enables users to save audio files in different formats, including MP3, WAV, and more
- Supports multiple languages, including English, Spanish, German, French, etc
- It offers a range of voices in different languages and accents to choose from
- NaturalReader is available for Windows and Mac platforms, online versions, and mobile apps
To know more about NaturalReader Text-To-Speech Software features and product options, click here to continue.
6. CereProc
CereProc is a text-to-speech software designed to quickly and accurately convert text into speech. It uses advanced artificial intelligence algorithms to convert written text into spoken words in various languages and voice styles. Users can use this software for many applications, including speech synthesis for the visually impaired, audiobooks, language learning, and interactive voice response systems.
In addition, the voices produced by CereProc text-to-speech software are highly customizable. They can be adapted to suit specific needs, such as adjusting the voice’s speed, pitch, and intonation.
Key Features:
- Users can integrate with various applications, such as accessibility tools, telephony systems, and educational software
- Available for Windows, MacOS, iOS, and Android platforms
- CereProc’s TTS voices are designed to sound as close to human speech as possible
- Supports multiple languages, including English, Spanish, French, German, etc
To know more about CereProc Text-To-Speech Tracking Software features and product options, click here to continue.
7. iSpeech
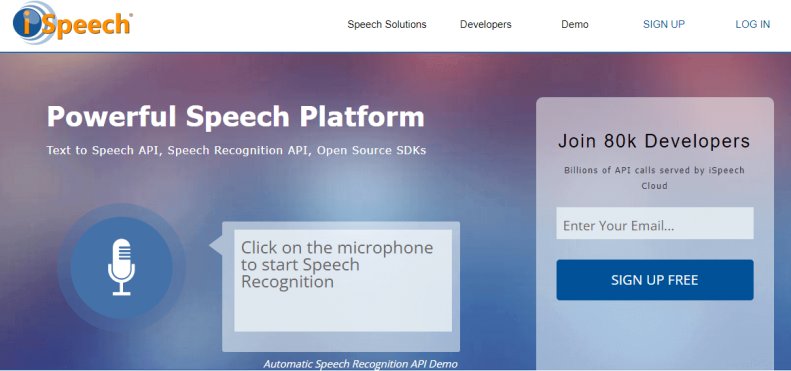
iSpeech is a cloud-based text-to-speech and speech recognition technology allowing users to convert written text into speech. Offers APIs and software development kits that developers can use to integrate text-to-speech functionality into their applications and websites. Supports multiple file formats, including MP3, WAV, and OGG, allowing users to save TTS output in their preferred format. In addition, iSpeech text-to-speech software allows users to customize the TTS output, such as the voice tone, speed, and volume, to meet their specific needs.
Key Features:
- It is known for producing high-quality and natural-sounding natural-sounding voices in multiple languages and accents
- Available on cloud-based or embedded solutions within applications
- Supports multiple platforms, including Windows, Linux, macOS, iOS, and Android
- Supports multiple languages, such as English, Spanish, French, German, Italian, etc
To know more about iSpeech Text-To-Speech Software features and product options, click here to continue.
8. Nuance Vocalizer
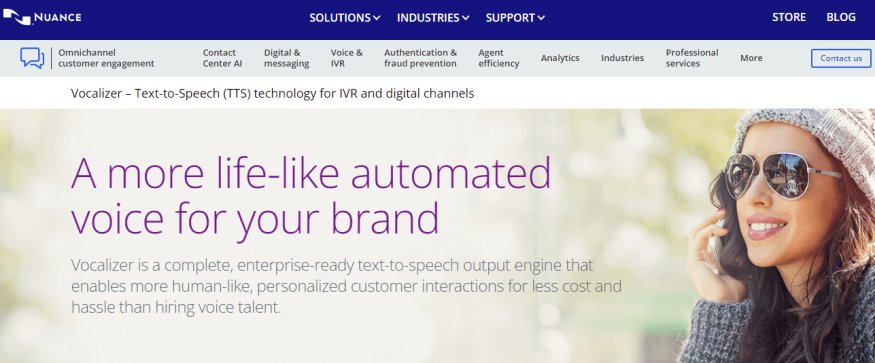
Nuance Vocalizer is a text-to-speech software that converts written text into speech. It converts written text into spoken words, enabling users to listen to digital content such as e-books, news articles, and website content. Vocalizer uses natural language processing (NLP) and deep learning algorithms to produce realistic, high-quality speech.
Nuance Vocalizer text-to-speech software can be integrated into various applications and services, such as virtual assistants, e-learning platforms, and customer service systems. In addition, it supports a wide range of platforms and devices, including Windows, Linux, macOS, iOS, and Android.
Key Features:
- Offers a range of customizable voice options, including gender, accent, and tone, to match the desired style and tone
- It uses advanced AI algorithms to create a human-like voice that is natural and engaging
- Vocalizer can be deployed on-premise, in the cloud, or as an embedded solution within applications
- Supports multiple languages, such as English, Spanish, French, German, Italian, etc
To know more about Nuance Vocalizer Text-To-Speech Software features and product options, click here to continue.
9. ReadSpeaker
ReadSpeaker is a text-to-speech (TTS) technology that allows written content to be read aloud by a computer-generated voice. It provides a natural-sounding voice for websites, mobile apps, e-books, and other digital content, making it more accessible for people with visual impairments, learning disabilities, or anyone who struggles with reading. Users can choose from different voices, with options for male or female voices, accents, and languages.
In addition, ReadSpeaker text-to-speech software provides a user-friendly interface that is easy to use and customize, allowing users to control the speed and volume of the speech and choose the text they want to read.
Key Features:
- Supports multiple languages, including English, Spanish, German, French, Italian, etc
- It uses advanced speech synthesis technology to generate speech that sounds more like a human voice
- Compliance with accessibility standards, such as Section 508 and WCAG, ensures that the technology is accessible to users with disabilities
- Provides a mobile app for iOS and Android mobiles
To know more about ReadSpeaker Text-To-Speech Software features and product options, click here to continue.
10. Acapela
Acapela TTS is text-to-speech software that converts written text into spoken words in real time, making it suitable for applications requiring fast and efficient text-to-speech conversion. It uses advanced speech synthesis technology to generate high-quality, natural, human-like speech. Provides a scalable solution that can be adapted to meet the needs of different users and applications. In addition, users can customize the speech output, such as speed, volume, and pronunciation.
Key Features:
- Allows users to integrate into various applications, such as e-learning platforms, assistive technology, and virtual assistants
- Supports various languages and dialects, including English, French, Spanish, German, Italian, etc
- Offers a range of customizable voices, allowing users to select the voice that best suits their needs
- Acapela can be used as a cloud-based service or on-premise
To know more about Acapela Text-To-Speech Software features and product options, click here to continue.
Conclusion
Text-To-Speech (TTS) Software is a versatile tool that continues to evolve and offers new possibilities for improving accessibility and communication for various users. For example, it can provide access to written content by converting it to spoken words for individuals with visual impairments or difficulties with reading. In addition, it provides a wide range of customization options, audio output options, and easy integration capabilities.
Featured Image Courtesy – Photo by ThisisEngineering RAEng on Unsplash
